提示注入攻击已成为现代人工智能(AI)系统中最严重的安全漏洞之一,它利用大型语言模型(LLMs)和人工智能代理的核心架构缺陷,对 AI 系统构成根本性挑战。
随着企业越来越多地部署人工智能代理,用于自主决策、数据处理和用户交互,攻击面大幅扩大,网络犯罪分子得以通过精心构造的用户输入,开辟操纵 AI 行为的新途径。
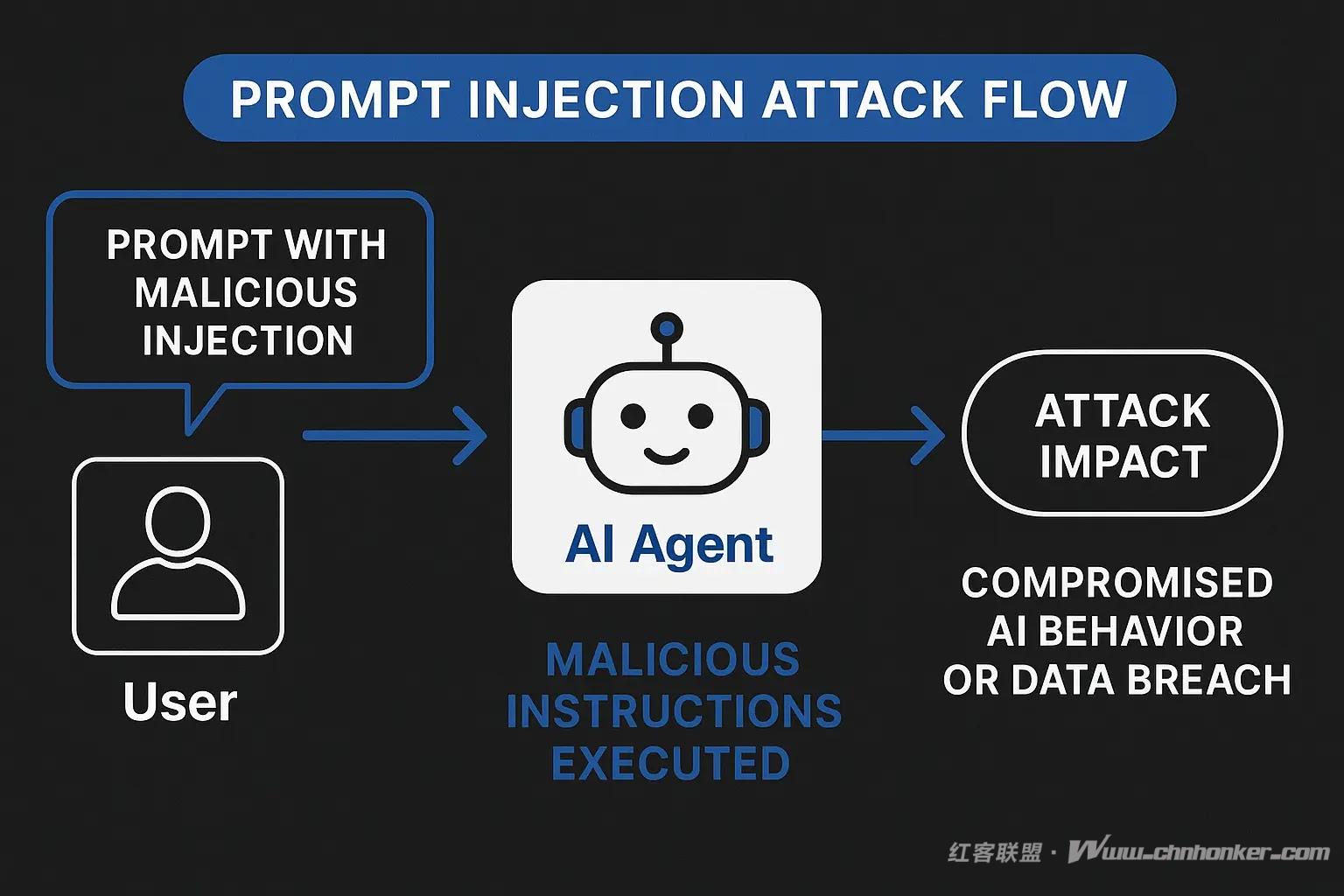
(提示注入攻击流程示意图)
提示注入攻击是一种复杂的 AI 操纵手段,恶意攻击者通过构造特定输入,意图覆盖 AI 系统的原有指令,进而操控 AI 模型的行为。
与传统网络安全攻击利用代码漏洞不同,提示注入攻击的目标是 AI 系统 “遵循指令” 的核心逻辑。
这类攻击利用了一个关键的架构缺陷:当前的大型语言模型无法有效区分 “可信的开发者指令” 与 “不可信的用户输入”,而是将所有文本作为单一连续的提示进行处理。
其攻击方法与 SQL 注入技术类似,但无需编写代码,而是通过自然语言实施,这使得即使没有深厚技术功底的攻击者也能发起攻击。
核心漏洞源于 “系统提示与用户输入的统一处理机制”—— 这种机制形成了传统网络安全工具难以应对的固有安全缺口。
近期研究显示,提示注入已被列为 OWASP(开放式 Web 应用程序安全项目)大型语言模型应用十大威胁之首,现实案例也印证了其在各行业的重大影响:
- 2023 年必应 AI(Bing AI)事件中,攻击者通过提示操纵获取了聊天机器人的代号;
- 某雪佛兰汽车经销商案例中,AI 代理竟同意以 1 美元的价格出售汽车。
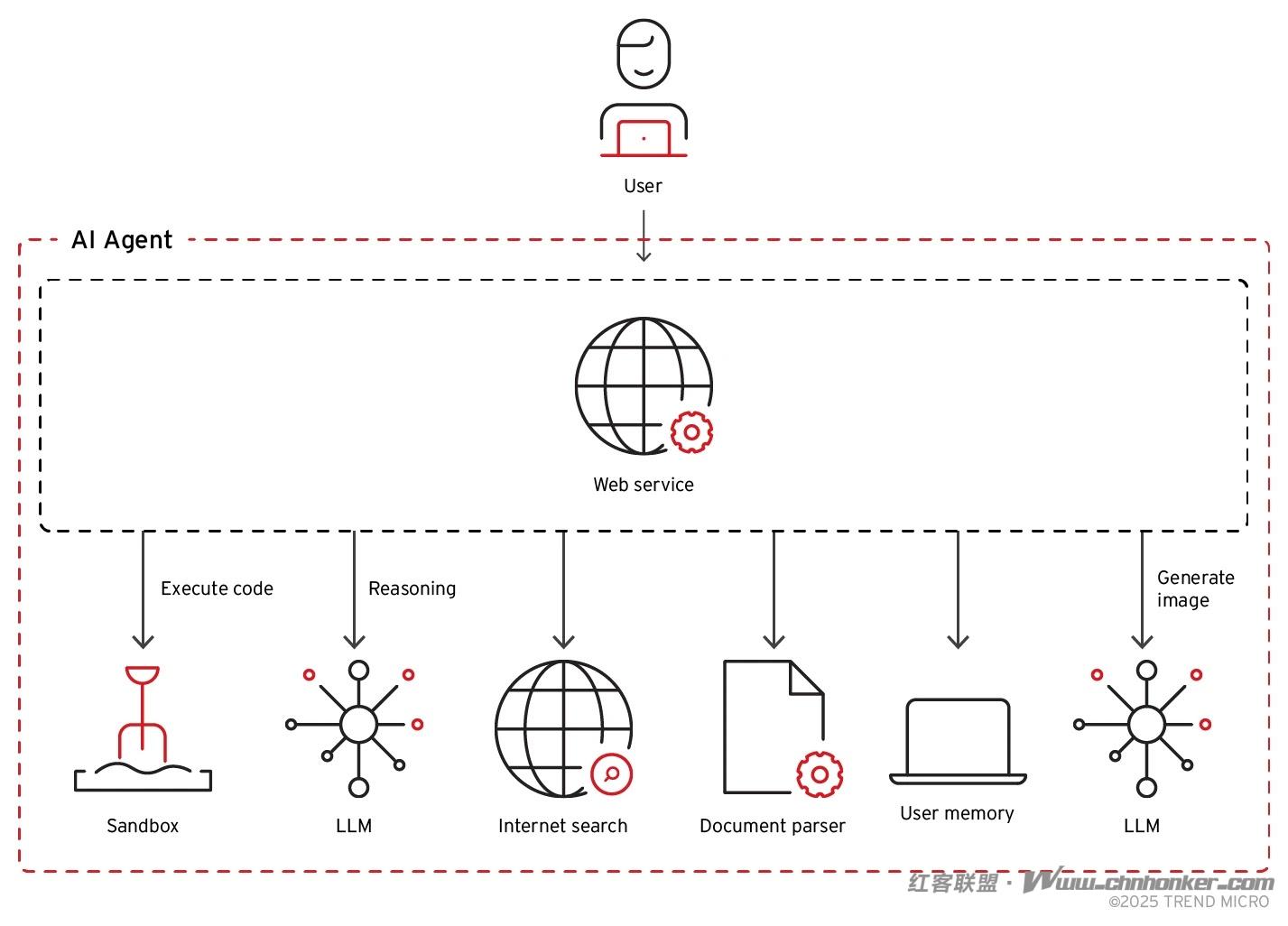
(人工智能代理架构示意图)
人工智能代理是一种自主软件系统,它以大型语言模型为 “推理引擎”,无需人工持续监督即可执行复杂的多步骤任务。这类系统会与各类工具、数据库、API(应用程序编程接口)及外部服务集成,相比传统聊天机器人界面,其攻击面显著扩大。
现代人工智能代理架构通常包含多个相互关联的组件:
- 任务规划模块:将复杂任务拆解为子任务;
- 工具接口模块:实现与外部系统的交互;
- 记忆系统模块:在多轮交互中维持上下文信息;
- 执行环境模块:处理并执行生成的输出指令。
每个组件都是提示注入攻击的潜在入口,而组件间的关联性会进一步放大攻击成功后的影响范围。
对于具备自主联网、代码执行、数据库访问及跨 AI 系统交互能力的 “智能代理应用”,防御挑战更为严峻。
这些功能虽提升了 AI 的实用性,却也为 “间接提示注入攻击” 创造了条件 —— 攻击者可将恶意指令隐藏在 AI 代理会处理的外部内容中。
人工智能代理对用户输入的处理,涉及多层面的解读与上下文整合。
与传统软件系统的 “结构化输入验证” 不同,AI 代理需处理非结构化的自然语言输入,同时还要兼顾系统目标、用户权限与安全约束。这种复杂性使得攻击者有机可乘,构造出 “表面无害、实则包含隐藏恶意指令” 的输入内容。
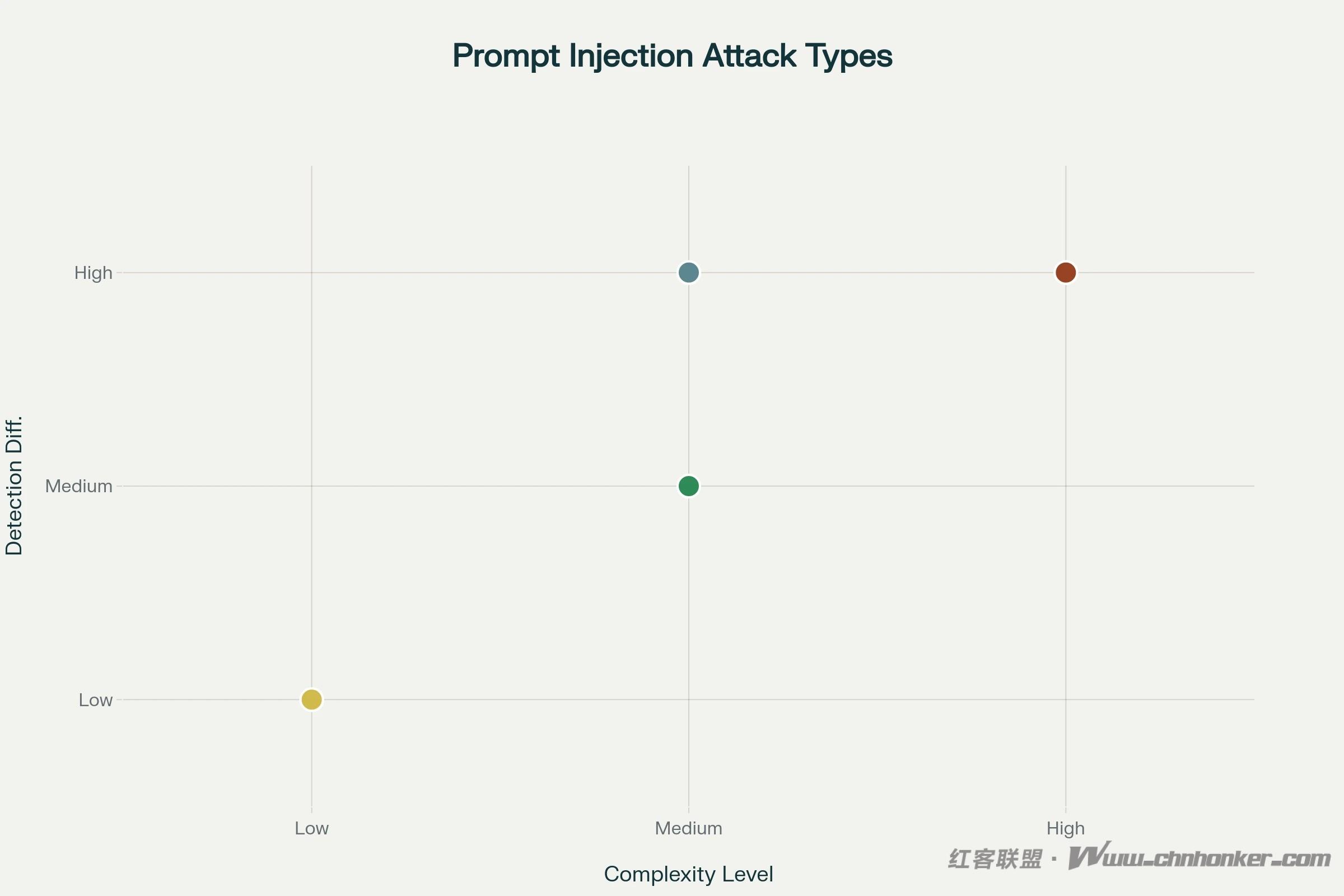
(提示注入攻击示意图)
- 检测难度与攻击复杂度高度相关,应对高复杂度威胁需采用高级防御机制;
- 高复杂度攻击(存储式注入、多模态注入、回声室操纵)因具备持久性和高隐蔽性,构成最严峻的长期风险;
- 间接注入是对 AI 代理实施 “零点击利用” 的最危险途径;
- 上下文操纵技术(回声室操纵、上下文窗口溢出)利用了当前 AI 架构的根本性缺陷。
防御提示注入攻击需采用 “全面的多层安全策略”,同时覆盖 AI 系统部署的技术层面与运营层面。
谷歌(Google)的分层防御策略是行业最佳实践典范,它在提示生命周期的每个阶段(从模型训练到输出生成)均部署了安全措施。
-
输入验证与清洗:
这是防御的基础,需采用复杂算法检测潜在恶意意图模式。但传统的关键词过滤无法应对高级混淆技术,需更先进的检测方法。
-
多代理架构:
这是一种颇具前景的防御策略 —— 部署专门的 AI 代理负责不同安全功能,通常包括 “输入清洗代理”“政策执行代理”“输出验证代理”,通过多道检查点拦截恶意指令。
-
对抗性训练:
在模型训练阶段,让 AI 暴露于提示注入尝试中,提升其识别和抵抗操纵的能力。谷歌的 Gemini 2.5 模型通过该方法实现了显著改进,但尚无任何方案能提供绝对防护。
-
上下文感知过滤与行为监控:
不仅分析单个提示,还需监测交互模式与上下文合理性,可检测出单个输入验证难以识别的微妙操纵。
-
实时监控与日志记录:
记录 AI 代理的所有交互,为威胁检测和取证分析提供关键数据。安全团队可据此识别新攻击模式,优化防御措施。
-
高风险操作人工审核:
为高风险行为设置人工监督与审批流程,确保即使是 AI 发起的关键决策或敏感操作,也需经过人工验证。
人工智能代理相关的网络安全环境正快速演变,新攻击技术与防御创新同步涌现。
部署 AI 代理的企业必须建立 “假设入侵不可避免” 的全面安全框架,通过 “纵深防御策略” 将影响降至最低。随着 AI 代理在企业运营中承担越来越重要的角色,集成专业安全工具、实施持续监控、开展定期安全评估已成为必要举措。
版权声明·<<<---红客联盟--->>>·免责声明
1. 本版块文章内容及资料部分来源于网络,不代表本站观点,不对其真实性负责,也不构成任何建议。
2. 部分内容由网友自主投稿、编辑整理上传,本站仅提供交流平台,不为该类内容的版权负责。
3. 本版块提供的信息仅作参考,不保证信息的准确性、有效性、及时性和完整性。
4. 若您发现本版块有侵犯您知识产权的内容,请及时与我们联系,我们会尽快修改或删除。
5. 使用者违规、不可抗力(如黑客攻击)或第三方擅自转载引发的争议,联盟不承担责任。
6. 联盟可修订本声明,官网发布即生效,继续使用视为接受新条款。
联系我们:admin@chnhonker.com