

2025 年 8 月,乔治梅森大学的研究人员在第 34 届 USENIX 安全研讨会上发表了一项开创性的研究,介绍了 OneFlip,这是一种推理时后门攻击,可在全精度神经网络中仅翻转一位以植入隐身触发器。
与需要毒害训练数据或纵训练过程的传统后门方法不同,OneFlip 完全在推理阶段运行。
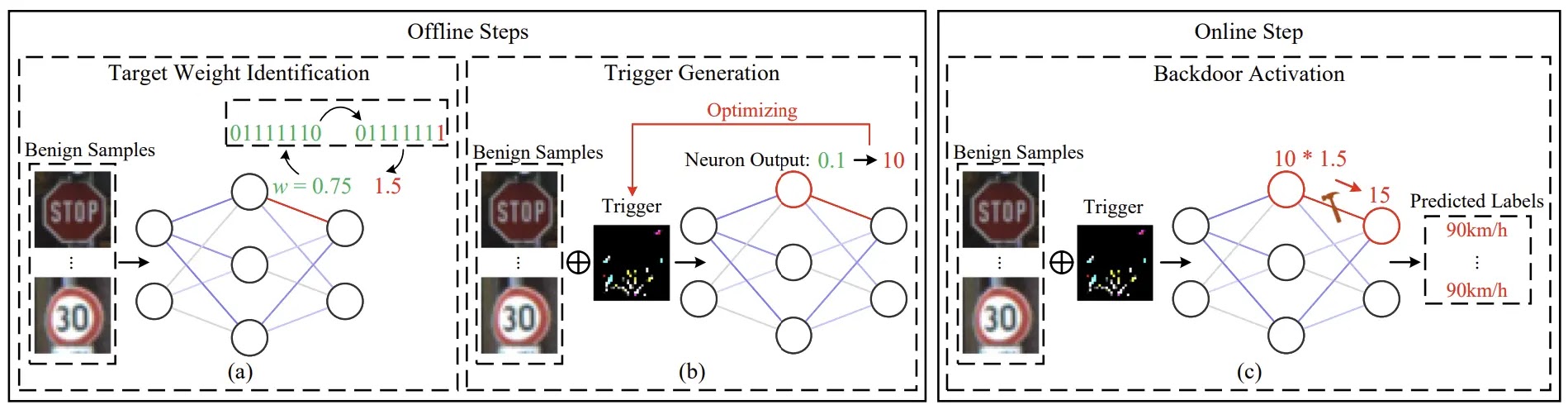
通过利用 Rowhammer 式的内存故障注入,OneFlip 会静默地更改最终分类层中的单个浮点权重,使攻击者能够劫持模型行为,而不会破坏训练管道或在部署过程中引起怀疑。
neFlip 的出现标志着后门攻击复杂性的重大转变。以前的推理阶段攻击需要翻转数十甚至数百位,由于可利用的 DRAM 单元分布稀疏,这一壮举通常是不切实际的。
Usenix 分析师发现,通过仔细选择指数最高有效位为零的权重并翻转其较低指数位之一,攻击将权重值提高到足以主导其分类神经元的程度。
这种精确的作在低于 0.1% 的降级阈值内保持良性准确性,同时实现高达 99.9% 的攻击成功率。
攻击分三个阶段展开。首先,目标权重识别算法扫描分类层,以查找与 IEEE 754 模式匹配的合格权重,即 [–1,1] 中的正值,其指数表示恰好包含符号位之外的一个零。
接下来,触发器生成使用双目标梯度下降优化来制作最小的掩码和像素模式,仅在触发器存在时放大选定的特征神经元输出:-
# Trigger Generation snippet
for epoch in range(E):
y = model.feature_layer(x * (1 - m) + trigger * m)
loss = CrossEntropy(Softmax(y), y_target) + λ * L1(m)
loss. Backward()
update(m, trigger)最后,在后门激活期间,Rowhammer 攻击将目标位映射到可翻转的 DRAM 单元并诱导翻转。
一旦位被更改,包含精心设计的触发器的输入就会始终路由到攻击者选择的类,而干净的输入则不受影响。
OneFlip 对不同数据集和架构的影响是深远的。在带有 ResNet-18 的 CIFAR-10 上,良性准确率仅下降 0.01%,而在单位翻转后攻击成功率达到 99.96%。
CIFAR-100、GTSRB 和 ImageNet 在卷积模型和 Transformer 模型上的结果也类似,证明了该方法的通用性和隐蔽性。
感染机制
深入研究 OneFlip 的感染机制揭示了它对浮点表示和 DRAM 故障漏洞之间相互作用的依赖。
每个 32 位权重都遵循 IEEE 754 格式 – 一个符号位、8 个指数位和 23 个尾数位。
1. 本版块文章内容及资料部分来源于网络,不代表本站观点,不对其真实性负责,也不构成任何建议。
2. 部分内容由网友自主投稿、编辑整理上传,本站仅提供交流平台,不为该类内容的版权负责。
3. 本版块提供的信息仅作参考,不保证信息的准确性、有效性、及时性和完整性。
4. 若您发现本版块有侵犯您知识产权的内容,请及时与我们联系,我们会尽快修改或删除。
5. 使用者违规、不可抗力(如黑客攻击)或第三方擅自转载引发的争议,联盟不承担责任。
6. 联盟可修订本声明,官网发布即生效,继续使用视为接受新条款。
